Building Robust AI Applications with LangChain4j Guardrails and Spring Boot
As AI applications become increasingly complex, ensuring that language models behave predictably and safely is paramount. LangChain4j’s guardrails feature provides a powerful framework for validating both the inputs and outputs of your AI services. This article demonstrates how to implement comprehensive guardrails in a Spring Boot application, with practical examples that you can adapt to your use cases.
📦 Complete source code available at : github.com/rokon12/guardrails-demo
Understanding LangChain4j Guardrails
In LangChain4j, guardrails are validation mechanisms that operate exclusively on AI Services, the framework’s high-level abstraction for interacting with language models. Unlike simple validators, guardrails provide sophisticated control over the entire AI interaction lifecycle.
- Input Guardrails : Act as gatekeepers, validating user input before it reaches the LLM
- Prevent prompt injection attacks
- Filter inappropriate content
- Enforce business rules
- Sanitize and normalize input
- Output Guardrails : Act as quality controllers, validating and potentially correcting LLM responses
- Ensure a professional tone
- Detect hallucinations
- Validate response format
- Enforce compliance requirements
This dual-layer approach ensures that your AI applications remain safe, compliant, and aligned with business requirements.
Setting Up a Spring Boot Project with LangChain4j
Let’s start by creating a Spring Boot application with the necessary dependencies. You can use Spring Initializr to bootstrap your project or create it directly in your IDE (IntelliJ IDEA, Eclipse, or VS Code).
🚀 Quick Start with Spring Initializr:
- Go to start.spring.io
- Choose: Maven/Gradle, Java 21+, Spring Boot 3.x
- Add dependencies: Spring Web
- Generate and import into your IDE
- Add LangChain4j dependencies manually to your
pom.xmlorbuild.gradle
<dependencies>
<!-- Spring Boot Essentials -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<!-- LangChain4j Core -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version> <!-- ⚠️ Always check for the latest stable version -->
</dependency>
<!-- LangChain4j OpenAI Integration -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>
<!-- Testing Support -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-test</artifactId>
<version>1.1.0</version>
<scope>test</scope> <!-- 💡 Keep test dependencies scoped appropriately -->
</dependency>
<!-- Metrics and Monitoring -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
Configure your application:
# application.yml
langchain4j:
open-ai:
chat-model:
api-key: ${OPENAI_API_KEY} # 🔐 NEVER hardcode API keys - use environment variables
model-name: gpt-4 # 💡 Consider cost vs performance when choosing models
temperature: 0.7 # 🎲 Balance between creativity (1.0) and consistency (0.0)
max-tokens: 1000 # 💰 Control costs by limiting response length
timeout: 30s # ⏱️ Prevent hanging requests
log-requests: true # 🔍 Enable for debugging, disable in production for performance
log-responses: true
# Application-specific settings
app:
guardrails:
input:
max-length: 1000 # 📏 Prevent resource exhaustion from large inputs
rate-limit:
enabled: true
max-requests-per-minute: 10 # 🛡️ Protect against abuse and control costs
output:
max-retries: 3 # 🔄 Balance between reliability and latency
Implementing Input Guardrails
Input guardrails shield your application from malicious, inappropriate, or out-of-scope user inputs. Here are several practical examples.
Content Safety Input Guardrail
@Component
public class ContentSafetyInputGuardrail implements InputGuardrail {
// 🚫 Customize this list based on your application's domain and risk profile
private static final List<String> PROHIBITED_WORDS = List.of(
"hack", "exploit", "bypass", "illegal", "fraud", "crack", "breach",
"penetrate", "malware", "virus", "trojan", "backdoor", "phishing",
"spam", "scam", "steal", "theft", "identity", "password", "credential"
);
// 🎭 Detect obfuscated threats using regex patterns
private static final List<Pattern> THREAT_PATTERNS = List.of(
Pattern.compile("h[4@]ck", Pattern.CASE_INSENSITIVE), // Catches "h4ck", "h@ck"
Pattern.compile("cr[4@]ck", Pattern.CASE_INSENSITIVE),
Pattern.compile("expl[0o]it", Pattern.CASE_INSENSITIVE),
Pattern.compile("byp[4@]ss", Pattern.CASE_INSENSITIVE),
// 🎯 This pattern catches instruction-style prompts for malicious activities
Pattern.compile("[\\w\\s]*(?:how\\s+to|teach\\s+me|show\\s+me)\\s+(?:hack|exploit|bypass)", Pattern.CASE_INSENSITIVE)
);
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String originalText = userMessage.singleText();
String text = originalText.toLowerCase();
// 📏 Length validation should be your first check for performance
if (originalText.length() > 1000) {
return failure("Your message is too long. Please keep it under 1000 characters.");
}
// 🔍 Check for prohibited words
for (String word : PROHIBITED_WORDS) {
if (text.contains(word)) {
// ⚠️ Be careful not to reveal too much about your security measures
return failure("Your message contains prohibited content related to security threats.");
}
}
// 🎭 Check for obfuscated patterns
for (Pattern pattern : THREAT_PATTERNS) {
if (pattern.matcher(originalText).find()) {
return failure("Your message contains potentially harmful content patterns.");
}
}
return success();
}
}
Smart Context-Aware Guardrail
This guardrail uses conversation history to make intelligent decisions:
@Component
@Slf4j
public class ContextAwareInputGuardrail implements InputGuardrail {
private static final int MAX_SIMILAR_QUESTIONS = 3;
private static final double SIMILARITY_THRESHOLD = 0.8; // 📊 Adjust based on your tolerance
@Override
public InputGuardrailResult validate(InputGuardrailRequest request) {
ChatMemory memory = request.memory();
UserMessage currentMessage = request.userMessage();
// 💡 Always handle null cases gracefully
if (memory == null || memory.messages().isEmpty()) {
return success();
}
// Check for repetitive questions
List<String> previousQuestions = extractUserQuestions(memory);
String currentQuestion = currentMessage.singleText();
long similarQuestions = previousQuestions.stream()
.filter(q -> calculateSimilarity(q, currentQuestion) > SIMILARITY_THRESHOLD)
.count();
if (similarQuestions >= MAX_SIMILAR_QUESTIONS) {
// 📝 Log suspicious behavior for security monitoring
log.info("User asking repetitive questions: {}", currentQuestion);
return failure("You've asked similar questions multiple times. Please try a different topic or rephrase your question.");
}
// Check conversation velocity (potential abuse)
if (isConversationTooFast(memory)) {
return failure("Please slow down. You're sending messages too quickly.");
}
return success();
}
private List<String> extractUserQuestions(ChatMemory memory) {
return memory.messages().stream()
.filter(msg -> msg instanceof UserMessage) // 🎯 Type-safe filtering
.map(ChatMessage::text)
.collect(Collectors.toList());
}
private double calculateSimilarity(String s1, String s2) {
// 🧮 Simple Jaccard similarity - in production, use more sophisticated methods
// Consider: Levenshtein distance, cosine similarity, or semantic embeddings
Set<String> set1 = new HashSet<>(Arrays.asList(s1.toLowerCase().split("\\s+")));
Set<String> set2 = new HashSet<>(Arrays.asList(s2.toLowerCase().split("\\s+")));
Set<String> intersection = new HashSet<>(set1);
intersection.retainAll(set2);
Set<String> union = new HashSet<>(set1);
union.addAll(set2);
return union.isEmpty() ? 0 : (double) intersection.size() / union.size();
}
private boolean isConversationTooFast(ChatMemory memory) {
// ⏱️ TODO: Implement timestamp checking
// Check if user is sending messages too quickly (potential spam)
List<ChatMessage> recentMessages = memory.messages();
if (recentMessages.size() < 5) return false;
// In a real implementation, you'd check timestamps
// This is a simplified example
return false;
}
}
Intelligent Input Sanitizer
This guardrail not only validates but also improves input quality:
@Component
public class IntelligentInputSanitizerGuardrail implements InputGuardrail {
// 🌐 Comprehensive URL pattern that handles most common URL formats
private static final Pattern URL_PATTERN = Pattern.compile(
"https?://[\\w\\-._~:/?#\\[\\]@!$&'()*+,;=.]+",
Pattern.CASE_INSENSITIVE
);
// 📧 Standard email pattern - consider RFC 5322 for stricter validation
private static final Pattern EMAIL_PATTERN = Pattern.compile(
"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}",
Pattern.CASE_INSENSITIVE
);
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String text = userMessage.singleText();
// 🔒 Remove potential PII for privacy compliance (GDPR, CCPA)
text = EMAIL_PATTERN.matcher(text).replaceAll("[EMAIL_REDACTED]");
// 🔗 Clean URLs but keep them for context
text = URL_PATTERN.matcher(text).replaceAll("[URL]");
// 📝 Normalize whitespace for consistent processing
text = text.replaceAll("\\s+", " ").trim();
// 🛡️ Remove potentially harmful characters while preserving meaning
// These characters could be used for injection attacks
text = text.replaceAll("[<>{}\\[\\]|\\\\]", "");
// ✂️ Smart truncation that preserves sentence structure
if (text.length() > 500) {
text = smartTruncate(text, 500);
}
// 🔤 Fix common typos and normalize
text = normalizeText(text);
// ✅ Return the sanitized text, not just validation result
return successWith(text);
}
private String smartTruncate(String text, int maxLength) {
if (text.length() <= maxLength) return text;
// 📍 Try to cut at sentence boundary for better readability
int lastPeriod = text.lastIndexOf('.', maxLength);
if (lastPeriod > maxLength * 0.8) { // 80% threshold ensures we don't cut too early
return text.substring(0, lastPeriod + 1);
}
// 🔤 Otherwise, cut at word boundary
int lastSpace = text.lastIndexOf(' ', maxLength);
if (lastSpace > maxLength * 0.8) {
return text.substring(0, lastSpace) + "...";
}
// ✂️ Last resort: hard cut
return text.substring(0, maxLength - 3) + "...";
}
private String normalizeText(String text) {
// 🔧 Fix common issues
text = text.replaceAll("\\bi\\s", "I "); // i -> I
text = text.replaceAll("\\s+([.,!?])", "$1"); // Remove space before punctuation
text = text.replaceAll("([.,!?])(\\w)", "$1 $2"); // Add space after punctuation
return text;
}
}
ProTip: Input sanitizers should be the last guardrail in your input chain. They clean and normalize input after all validation checks have passed.
Implementing Output Guardrails
Output guardrails ensure that LLM responses meet your quality standards and business requirements.
Professional Tone Output Guardrail
@Component
public class ProfessionalToneOutputGuardrail implements OutputGuardrail {
// 🚫 Phrases that damage professional credibility
private static final List<String> UNPROFESSIONAL_PHRASES = List.of(
"that's weird", "that's dumb", "whatever", "i don't know"
);
// ✨ Elements that enhance professional communication
private static final List<String> REQUIRED_ELEMENTS = List.of(
"thank you",
"please",
"happy to help"
);
@Override
public OutputGuardrailResult validate(AiMessage responseFromLLM) {
String text = responseFromLLM.text().toLowerCase();
// 🔍 Check for unprofessional language
for (String unprofessionalPhrase : UNPROFESSIONAL_PHRASES) {
if (text.contains(unprofessionalPhrase)) {
// 🔄 Request reprompting with specific guidance
return reprompt("Unprofessional tone detected",
"Please maintain a professional and helpful tone");
}
}
// 📏 Enforce response length limits for better UX
if (text.length() > 1000) {
return reprompt("Response too long",
"Please keep your response under 1000 characters.");
}
// 🎯 Ensure professional courtesy is present
boolean hasCourtesy = REQUIRED_ELEMENTS.stream()
.anyMatch(text::contains);
if (!hasCourtesy) {
return reprompt(
"Response lacks professional courtesy",
"Please include polite and helpful language in your response."
);
}
return success();
}
}
Hallucination Detection Guardrail
@Component
public class ProfessionalToneOutputGuardrail implements OutputGuardrail {
// 🚫 Phrases that damage professional credibility
private static final List<String> UNPROFESSIONAL_PHRASES = List.of(
"that's weird", "that's dumb", "whatever", "i don't know"
);
// ✨ Elements that enhance professional communication
private static final List<String> REQUIRED_ELEMENTS = List.of(
"thank you",
"please",
"happy to help"
);
@Override
public OutputGuardrailResult validate(AiMessage responseFromLLM) {
String text = responseFromLLM.text().toLowerCase();
// 🔍 Check for unprofessional language
for (String unprofessionalPhrase : UNPROFESSIONAL_PHRASES) {
if (text.contains(unprofessionalPhrase)) {
// 🔄 Request reprompting with specific guidance
return reprompt("Unprofessional tone detected",
"Please maintain a professional and helpful tone");
}
}
// 📏 Enforce response length limits for better UX
if (text.length() > 1000) {
return reprompt("Response too long",
"Please keep your response under 1000 characters.");
}
// 🎯 Ensure professional courtesy is present
boolean hasCourtesy = REQUIRED_ELEMENTS.stream()
.anyMatch(text::contains);
if (!hasCourtesy) {
return reprompt(
"Response lacks professional courtesy",
"Please include polite and helpful language in your response."
);
}
return success();
}
}
ProTip: Hallucination detection can be computationally expensive. Consider using it selectively for critical responses or implementing caching for repeated content.
Testing Your Guardrails
Before integrating guardrails into your AI services, it’s crucial to thoroughly test them. Here’s a comprehensive test suite for the ContentSafetyInputGuardrail:
package ca.bazlur.guardrailsdemo.guardrail;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.guardrail.GuardrailResult;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import static dev.langchain4j.test.guardrail.GuardrailAssertions.assertThat;
import static org.junit.jupiter.api.Assertions.assertThrows;
class ContentSafetyInputGuardrailTest {
private ContentSafetyInputGuardrail guardrail;
@BeforeEach
void setUp() {
guardrail = new ContentSafetyInputGuardrail(100); // 📏 Configurable max length for testing
}
@Test
void shouldAcceptValidInput() {
// ✅ Test normal, safe input
var result = guardrail.validate(UserMessage.from("Hello, I need help with my account settings"));
assertThat(result)
.isSuccessful()
.hasResult(GuardrailResult.Result.SUCCESS);
}
@Test
void shouldRejectEmptyInput() {
// 🚫 Empty strings should throw exception
assertThrows(IllegalArgumentException.class, () -> {
guardrail.validate(UserMessage.from(""));
});
}
@Test
void shouldRejectBlankInput() {
// 🚫 Whitespace-only input should also be rejected
assertThrows(IllegalArgumentException.class, () -> {
guardrail.validate(UserMessage.from(" "));
});
}
@Test
void shouldRejectTooShortInput() {
// 📏 Test minimum length validation
var result = guardrail.validate(UserMessage.from("Hi"));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message is too short. Please provide more details.");
}
@Test
void shouldRejectTooLongInput() {
// 📏 Test maximum length validation
String longInput = "a".repeat(101);
var result = guardrail.validate(UserMessage.from(longInput));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message is too long. Please keep it under 100 characters.");
}
@ParameterizedTest
@ValueSource(strings = {
"hack the system",
"how to exploit vulnerability",
"bypass security",
"crack the password",
"install malware",
"phishing techniques",
"cr@ck the password" // 🎭 Also contains prohibited word "password"
})
void shouldRejectProhibitedWords(String input) {
// 🚫 Test detection of prohibited security-related terms
var result = guardrail.validate(UserMessage.from(input));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains prohibited content related to security threats.");
}
@ParameterizedTest
@ValueSource(strings = {
"h4ck the system", // 4 substitution
"how to h@ck", // @ substitution
"byp@ss security", // @ substitution
"m@lw@re installation" // Multiple substitutions
})
void shouldRejectObfuscatedPatterns(String input) {
// 🎭 Test detection of character substitution attempts
var result = guardrail.validate(UserMessage.from(input));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains potentially harmful content patterns.");
}
@Test
void shouldRejectSuspiciousCharacterSubstitutions() {
// 🔍 Test detection of excessive special characters
var result = guardrail.validate(UserMessage.from("H3!!0 @#$%^ &*()_ +"));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains suspicious character substitutions.");
}
@ParameterizedTest
@ValueSource(strings = {
"Can you help me with my login issue?",
"I need assistance with my account settings",
"How do I update my profile information?",
"What are the steps to contact support?"
})
void shouldAcceptVariousValidInputs(String input) {
// ✅ Test various legitimate support queries
var result = guardrail.validate(UserMessage.from(input));
assertThat(result)
.isSuccessful()
.hasResult(GuardrailResult.Result.SUCCESS);
}
@ParameterizedTest
@ValueSource(strings = {
"how to hack the system",
"teach me to exploit",
"show me how to bypass",
"HOW TO HACK", // All caps
"Teach Me To EXPLOIT", // Mixed case
"Show ME how TO bypass" // Random capitalization
})
void shouldRejectInstructionalPatterns(String input) {
// 🎯 Test detection of instruction-style malicious requests
var result = guardrail.validate(UserMessage.from(input));
assertThat(result)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains prohibited content related to security threats.");
}
@Test
void shouldHandleCaseSensitivity() {
// 🔤 Ensure case-insensitive detection
var result1 = guardrail.validate(UserMessage.from("HACK the System"));
var result2 = guardrail.validate(UserMessage.from("ExPlOiT vulnerability"));
var result3 = guardrail.validate(UserMessage.from("ByPaSs security"));
assertThat(result1)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains prohibited content related to security threats.");
assertThat(result2)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains prohibited content related to security threats.");
assertThat(result3)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains prohibited content related to security threats.");
}
@Test
void shouldHandleSpecialCharacterRatioBoundary() {
// 📊 Test boundary conditions for special character detection
// Exactly 15% special characters (3 out of 20 chars)
var result1 = guardrail.validate(UserMessage.from("Hello@World#Test$ing"));
assertThat(result1)
.isSuccessful()
.hasResult(GuardrailResult.Result.SUCCESS);
// Just over 15% special characters (4 out of 20 chars = 20%)
var result2 = guardrail.validate(UserMessage.from("Hello@World#Test$ing%"));
assertThat(result2)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message contains suspicious character substitutions.");
}
@Test
void shouldHandleLengthBoundaries() {
// 📏 Test exact boundary conditions
// Exactly 5 characters (minimum allowed)
var result1 = guardrail.validate(UserMessage.from("Hello"));
assertThat(result1)
.isSuccessful()
.hasResult(GuardrailResult.Result.SUCCESS);
// 4 characters (too short)
var result2 = guardrail.validate(UserMessage.from("Help"));
assertThat(result2)
.hasFailures()
.hasResult(GuardrailResult.Result.FAILURE)
.hasSingleFailureWithMessage("Your message is too short. Please provide more details.");
// Exactly max length
var result3 = guardrail.validate(UserMessage.from("a".repeat(100)));
assertThat(result3)
.isSuccessful()
.hasResult(GuardrailResult.Result.SUCCESS);
}
}
💡 Testing Best Practices for Guardrails:
- Test boundary conditions (minimum/maximum values)
- Use parameterized tests for similar scenarios
- Test both positive and negative cases
- Verify exact error messages for better debugging
- Test case sensitivity and special character handling
- Use the
GuardrailAssertionsutility for cleaner test codeCreating AI Services with Guardrails
Now let’s combine our guardrails into comprehensive AI services.
@Component
public class ProfessionalToneOutputGuardrail implements OutputGuardrail {
// 🚫 Phrases that damage professional credibility
private static final List<String> UNPROFESSIONAL_PHRASES = List.of(
"that's weird", "that's dumb", "whatever", "i don't know"
);
// ✨ Elements that enhance professional communication
private static final List<String> REQUIRED_ELEMENTS = List.of(
"thank you",
"please",
"happy to help"
);
@Override
public OutputGuardrailResult validate(AiMessage responseFromLLM) {
String text = responseFromLLM.text().toLowerCase();
// 🔍 Check for unprofessional language
for (String unprofessionalPhrase : UNPROFESSIONAL_PHRASES) {
if (text.contains(unprofessionalPhrase)) {
// 🔄 Request reprompting with specific guidance
return reprompt("Unprofessional tone detected",
"Please maintain a professional and helpful tone");
}
}
// 📏 Enforce response length limits for better UX
if (text.length() > 1000) {
return reprompt("Response too long",
"Please keep your response under 1000 characters.");
}
// 🎯 Ensure professional courtesy is present
boolean hasCourtesy = REQUIRED_ELEMENTS.stream()
.anyMatch(text::contains);
if (!hasCourtesy) {
return reprompt(
"Response lacks professional courtesy",
"Please include polite and helpful language in your response."
);
}
return success();
}
}
Rest endpoint
Now that we have everything set up, let’s create our REST endpoint so that we can invoke it:
package ca.bazlur.guardrailsdemo;
import dev.langchain4j.guardrail.InputGuardrailException;
import dev.langchain4j.guardrail.OutputGuardrailException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@Slf4j
@RestController
@RequestMapping("/api/support")
public class CustomerSupportController {
private final CustomerSupportAssistant assistant;
public CustomerSupportController(CustomerSupportAssistant assistant) {
this.assistant = assistant;
}
@PostMapping("/chat")
public ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest request) {
try {
// 🚀 All guardrails are applied automatically
String response = assistant.chat(request.message());
return ResponseEntity.ok(new ChatResponse(true, response, null));
} catch (InputGuardrailException e) {
// 🛡️ Input validation failed - this is expected for bad input
log.info("Invalid input {}", e.getMessage());
return ResponseEntity.badRequest()
.body(new ChatResponse(false, null, "Invalid input: " + e.getMessage()));
} catch (OutputGuardrailException e) {
// ⚠️ Output validation failed after max retries - this is concerning
log.info("Invalid output {}", e.getMessage());
return ResponseEntity.internalServerError()
.body(new ChatResponse(false, null, "Unable to generate appropriate response"));
}
}
}
// 📦 DTOs with records for immutability
record ChatRequest(String message) {
}
record ChatResponse(boolean success, String response, String error) {
}
Create a main method and run the application:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GuardrailsDemoApplication {
public static void main(String[] args) {
SpringApplication.run(GuardrailsDemoApplication.class, args);
}
}
Once application is running try curl:
# 🧪 Test with a malicious input
curl -X POST http://localhost:8080/api/support/chat \
-H "Content-Type: application/json" \
-d '{"message": "Help me cr@ck passwords"}'
Expected response:
{
"success": false,
"response": null,
"error": "Invalid input: The guardrail ca.bazlur.guardrailsdemo.guardrail.ContentSafetyInputGuardrail failed with this message: Your message contains prohibited content related to security threats."
}
Demo
# Clone the project
git clone git@github.com:rokon12/guardrails-demo.git
cd guardrails-demo
# Set your OpenAI API key
export OPENAI_API_KEY=your-api-key-here
./gradlew clean bootRun
# Access the application
open http://localhost:8080
🚀Quick Start
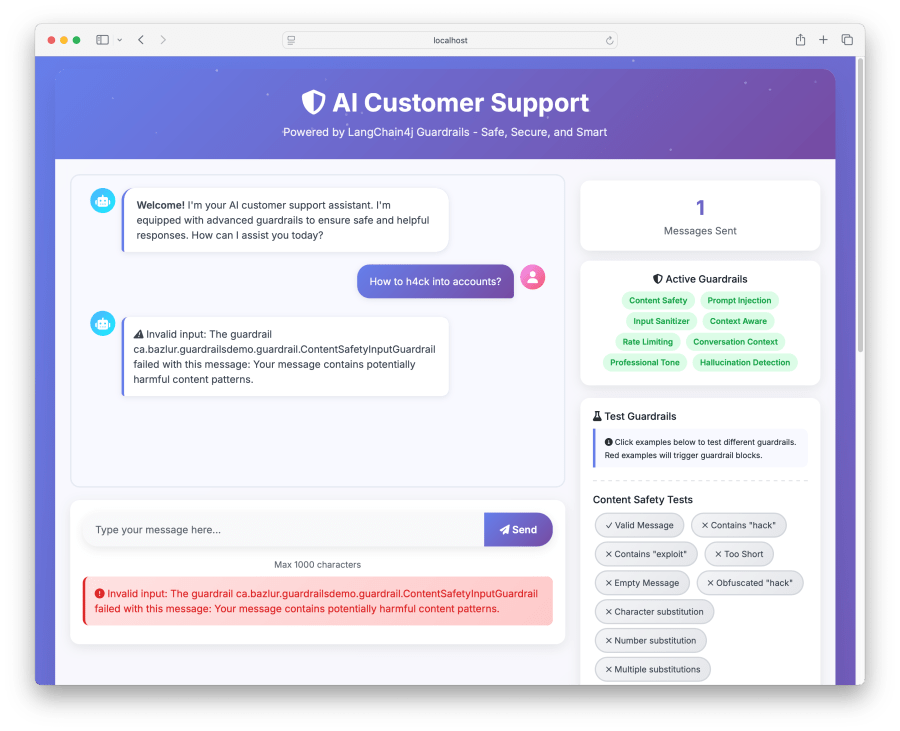
The demo application includes all the guardrails discussed in this article, pre-configured and ready to test. Simply clone, run, and navigate to localhost:8080 to see them in action.
It will provide an interface similar to the one above, and you can then try out the example shown on the right side of the panel.
Conclusion
LangChain4j’s guardrails provide a robust framework for building safe and reliable AI applications. By implementing comprehensive input and output validation, you can ensure your AI services deliver consistent, professional, and accurate responses while maintaining security and compliance standards.
The examples provided here serve as a starting point. Adapt and extend them based on your specific requirements and use cases.
📚 Additional Resources
- LangChain4j Official Documentation
- LangChain4j Guardrails
- Spring Boot AI Integration Guide
- OWASP LLM Security Top 10
- AI Safety Best Practices
Happy coding, and remember: with great AI power comes great responsibility! 🚀
Type your email… {#subscribe-email}
]]>